UPDATE: I wrote this post for Llama3.1, but just after I published it, Llama3.2 was released. It comes with similar performance but faster inference as it’s a distilled model(~2.6 times faster than Llama3.1 in a quick test I did). I updated this post to use 3.2 but it should work with any other version as well.
Zed is a great editor that supports AI assistants. In this post I will explain how you can share one Llama model you have running in a Mac between other computers in your local network for privacy and cost efficiency. Also, fans might get loud if you run Llama directly on the laptop you are using Zed as well.
Since I’ve found that Apple silicon (M1, M2, etc) is quite good at running these models, I will assume the model will be run in that computer. The default LLama3.2:3b works fine on a Mac Mini M1 with 16GB. If you have 8GB you might need to use simpler models.
The first step is to install ollama in your Mac. Just follow the instruction on the website. You will end up with a little llama icon on menu bar(top right). We now need to install a model, Llama3.2 in particular. In the terminal run this:
ollama run llama3.2This will try to run llama3.2 and since it is not yet installed, it will fetch the latest model for you. After it downloads and runs the model, simply type something to test it all works. It should look like this:
>>> Tell me a joke
Here's one:
What do you call a fake noodle?
An impasta.
>>> Send a message (/? for help)Now that it works locally we want to make it available for other computers in the local network. Open the terminal and run this command:
launchctl setenv OLLAMA_HOST 0.0.0.0:11434Now click on the icon and exit ollama. Then start ollama again. It should now be ready to accept connections from other computers in your network. To check connectivity, go to a Linux computer in your network and open a terminal. Run the following:
curl http://your_mac.local:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Tell me a joke",
"options": {
"num_ctx": 4096
}
}'Make sure you see a correct response before continuing. Now let’s configure Zed to use it. Open settings (CTRL-SHIFT-P and write open settings). Add these settings there (plus any others you already have, it’s a json file):
{
"language_models": {
"ollama": {
"api_url": "http://your_mac.local:11434",
"low_speed_timeout_in_seconds": 120,
"keep_alive": "120s",
"available_models": [
{
"provider": "ollama",
"name": "llama3.2:latest",
"max_tokens": 16384
}
]
}
},
"assistant": {
"default_model": {
"provider": "ollama",
"model": "llama3.2:latest"
},
"version": "2"
}
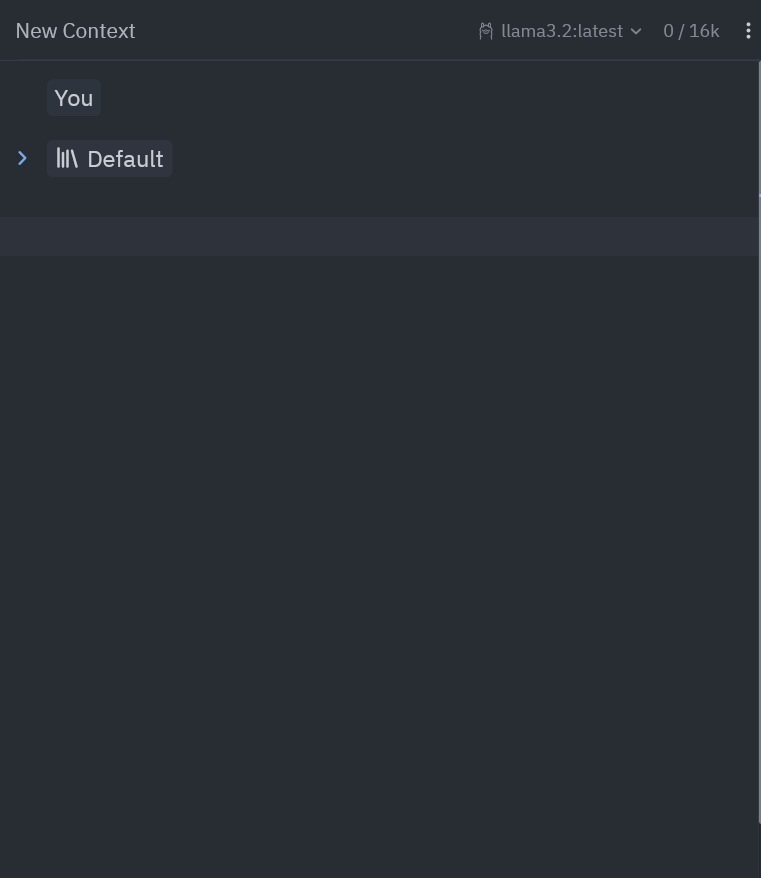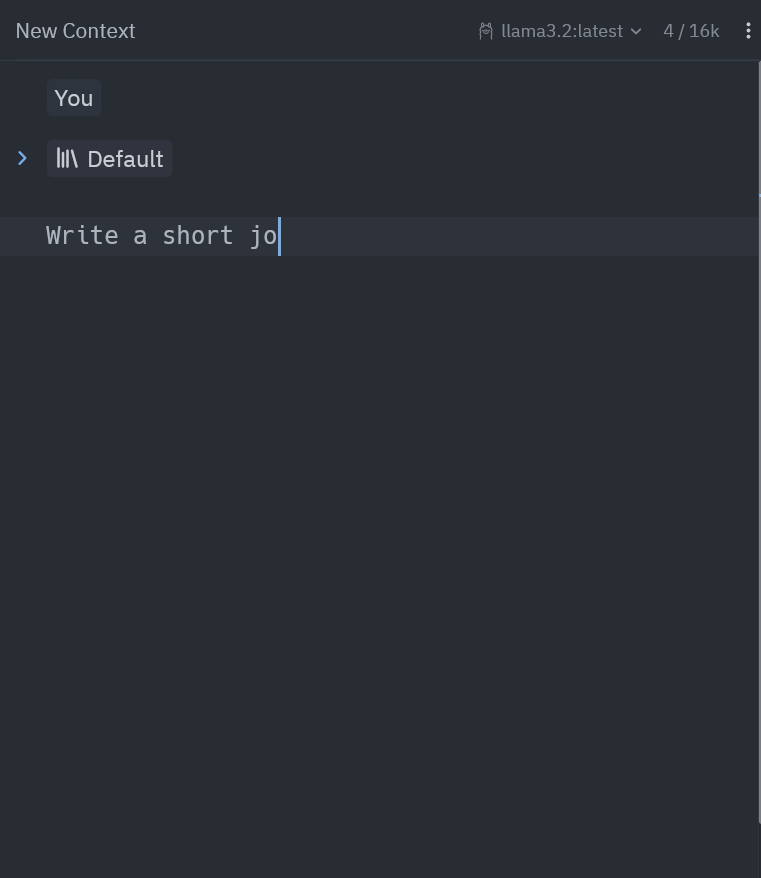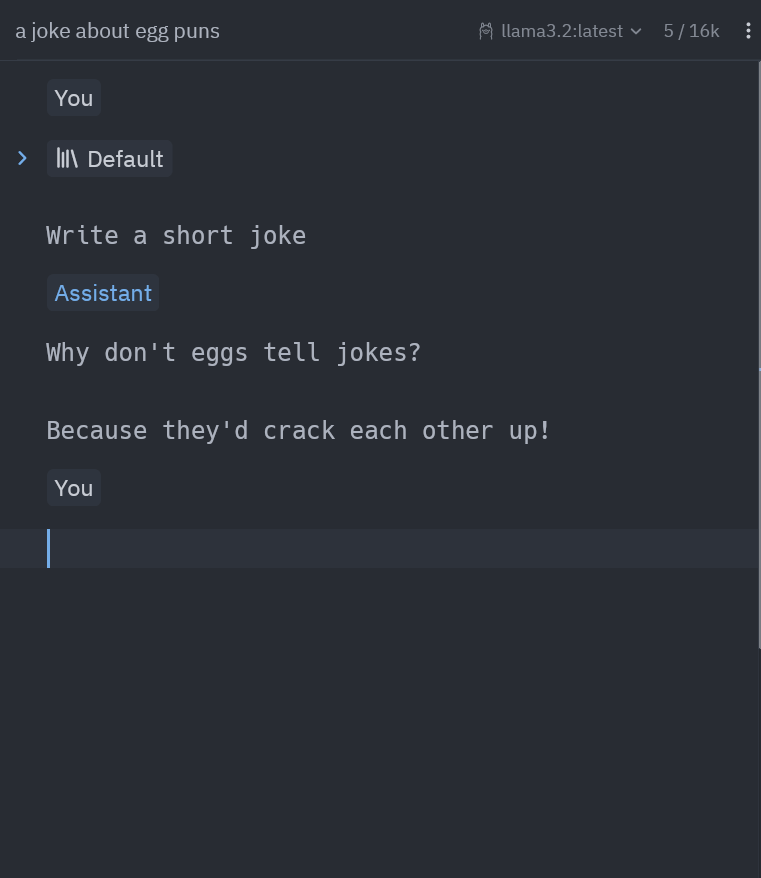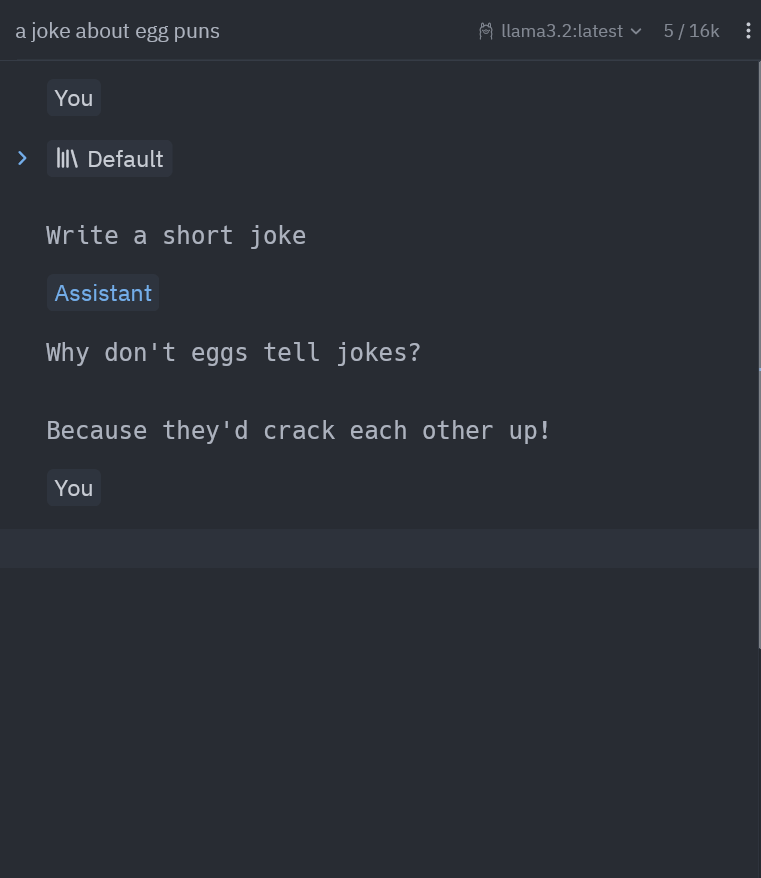
}It should now be configured. You can go to the Assistant Panel (CTRL+?) and ask whatever you want there. You can add context as well with /tab and others.
That’s it, now you have a shared Llama 3.2 model running in one computer, while using it on another computer in your network, privately and free, integrated into a great text editor.






0 Responses
Stay in touch with the conversation, subscribe to the RSS feed for comments on this post.